La première partie de cet article, dédié aux trois piliers de maturité pour l’entreprise data-driven, a permis de s’intéresser à l’organisation. Dans cette seconde partie, nous nous intéressons à l’architecture et à la gouvernance.
L’architecture : Privilégier le self-service, la flexibilité et la diversité des usages
Du fait de l’extrême diversité des cas d’usage, et malgré quelques exceptions qui confirment la règle comme pour la planification financière ou les customer data platforms, le domaine fonctionnel lié à la data ne s’est pas progicialisé. La maîtrise de l’architecture est donc une figure imposée, un exercice délicat qu’il est tentant de déléguer aux fournisseurs de technologie. C’est l’écueil à éviter, même si les progrès dans le monde de la data ont été provoqués par d’importantes vagues technologiques (data warehousing, business intelligence, puis le big data, le cloud et la data science). Mais, il incombe aux équipes data au sein de leur organisation de surfer (ou non) sur ces vagues vers des trajectoires qui non seulement répondent au contexte de leur organisation et de ses différents cas d’usage, mais lui permettent de progresser au fil des évolutions technologiques, organisationnelles et des besoins fonctionnels.
Pour y parvenir, cloud s’est rapidement imposé, parce qu’il a apporté souplesse et flexibilité, mais aussi démocratisé l’accès aux technologies, leur expérimentation et leur mise à l’échelle, y compris pour des organisations de taille modeste.
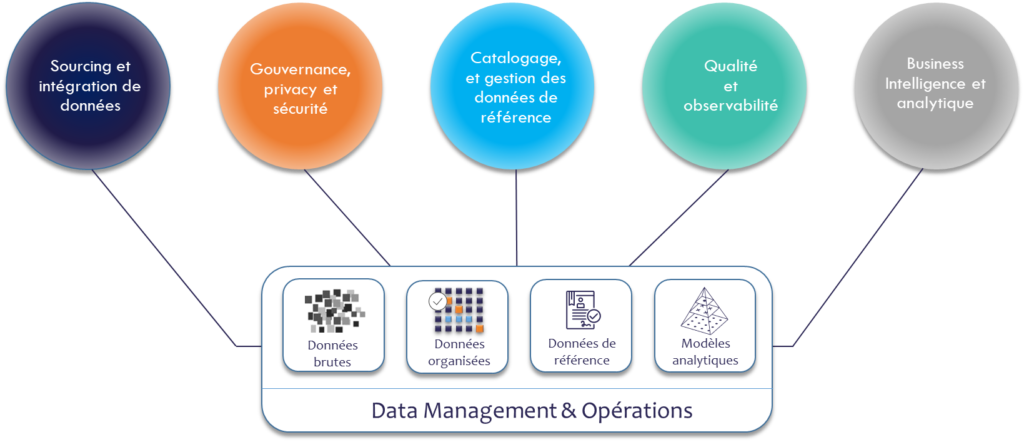
Historiquement organisé autour d’une base de données centrale privilégiant un accès aux données direct par les utilisateurs en mode self-service, la couche basse de l’architecture tend à se modulariser afin d’exploiter différents types de data, depuis les données brutes jusqu’aux données de référence, ou à celle qui sont modélisées spécifiquement pour certains cas d’usage. La plate-forme tend également à se virtualiser, afin de ne pas imposer une recopie systématique des données en autorisant la décentralisation ou la gestion des flux en temps réel.
En amont de ce socle, l’architecture doit permettre le sourcing et l’intégration de données, qui reste une fonction de back-office, pour les équipes de DataOps. En aval, elle doit autoriser un accès en libre-service au plus grand nombre, des analyses plus sophistiquées pour la data science, mais aussi des accès programmatiques pour alimenter en data et déclencher des actions dans les applications opérationnelles.
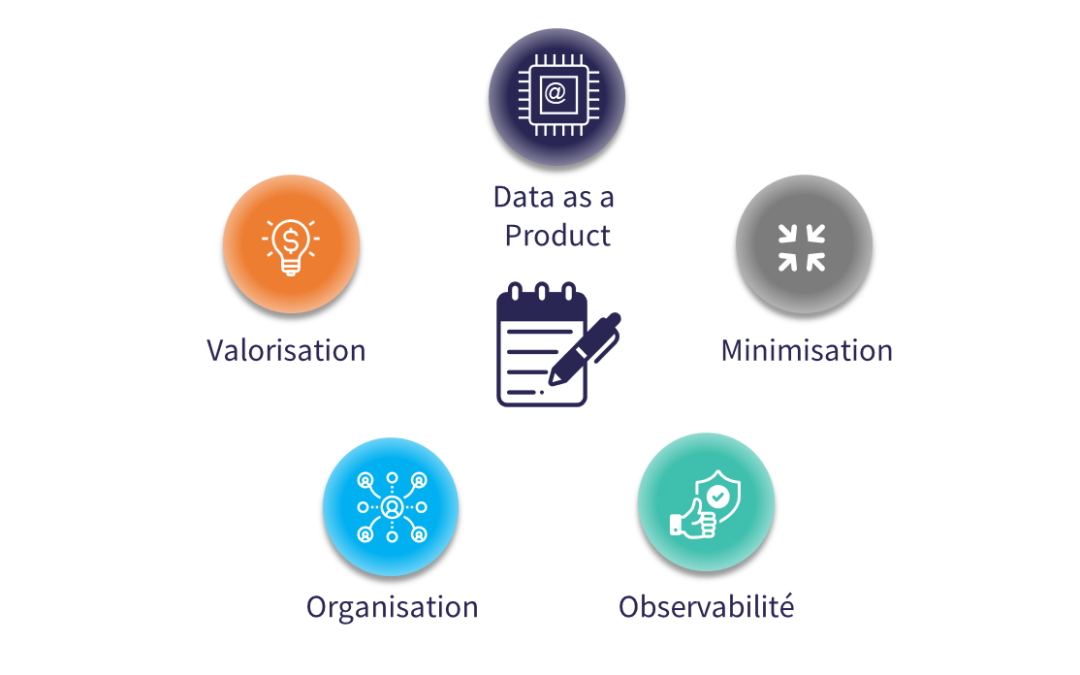
À ces trois dimensions de base, la tendance est d’en ajouter une quatrième, en support de la gouvernance et de la qualité, ainsi de l’accessibilité des données. Il s’agit non seulement de connecter les données réelles aux dispositifs de contrôle et de gestion de la qualité, mais aussi d’amener plus de transparence et de documentation aux données pour une utilisation en libre-service. Cette quatrième dimension inclut les capacités de gestion d’accès et de la sécurité, de provisioning, de gestion des données personnelles, et de catalogage ; sans oublier la qualité et l’observabilité des données, le potentiel tendon d’Achille des initiatives data dont les lacs de données se transforment parfois en marécages. Cette transparence passe par la constitution d’une couche sémantique permettant de référencer les données, de comprendre leur relation et leur origine, et de les associer à leur signification business et leur contexte fonctionnel. Le développement de cette dimension a jusque-là été freiné par le fait qu’elle sollicite fortement des ressources humaines, dans une approche déclarative. De récentes innovations technologiques permettent d’envisager plus d’automatisation et d’« intelligence », permettant d’installer cette couche supérieure au cœur de la plateforme de données moderne plutôt qu’en sa périphérie.
Définir un cadre pour la gouvernance et la qualité
Tout le monde s’accorde à dire que la gouvernance de données est un maillon essentiel de la réussite d’une initiative data. Mais, c’est souvent le maillon faible, tant il peut être délicat non pas seulement d’en définir le contour, mais surtout d’en transmettre et d’en faire respecter les principes. Un programme de gouvernance de données est transverse, et doit définir les rôles et responsabilités, les politiques, standards et processus, ainsi que les règles et contrôles. C’est un programme de transformation qui nécessite une gestion du changement, et donc d’en reconnaître la nécessité et les conséquences, puis d’engager les parties prenantes dans sa réalisation.
Le schéma ci-dessous présente un cadre pour la gouvernance, fortement mais librement du « modern governance framework » de Dave Wells.
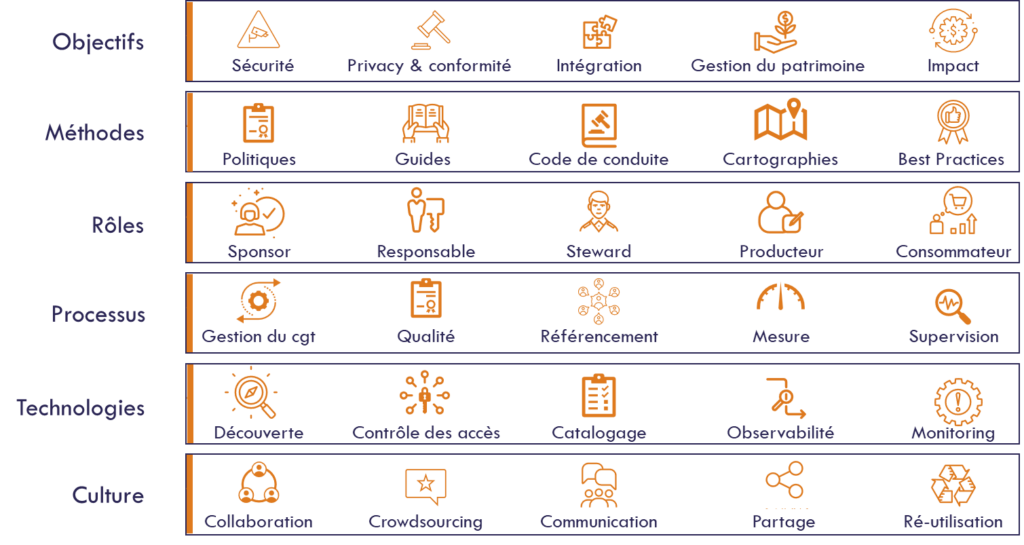
Tout commence par la formalisation du pourquoi et du comment aligner le programme sur les enjeux de l’entreprise. Cette partie est fondamentale pour obtenir l’adhésion des directions générales et l’engagement des parties prenantes.
Il faut ensuite développer les principes directeurs et les moyens pour les formaliser, tels que les codes de conduite ou les approches utilisées pour inventorier et cartographier les données. Puisque la gouvernance consiste le plus souvent à établir un système d’entités décisionnelles plutôt qu’un centre unique de décision, il faut clairement définir et répartir les rôles et responsabilités, et s’assurer de leur intégration dans l’organisation. D’autant que les rôles sont de plus en plus nombreux et diversifiées au fur et à mesure que les initiatives prennent de l’ampleur et augmentent leur impact.
Une fois le cadre et les rôles définis, il faut assurer sa mise en œuvre. Ceci passe par la définition des processus et des contrôles, par exemple pour établir le privacy by design, assurer et mesurer la qualité des données ou encore leur référencement systématique.
Même si elles ne doivent rester qu’un moyen, les technologies sont indispensables pour la mise à l’échelle. Les données sont surabondantes et évoluent en permanence, tandis que les ressources dédiées à la gouvernance sont limitées. Les technologies doivent permettre de connecter en permanence les règles du jeu, édictées et arbitrées par les personnes, avec les données proprement dites, pour permettre de s’assurer de leur mise en pratique et d’alerter dans le cas contraire.
Enfin, la data est un sport d’équipe, et les silos détruisent sa valeur. La data gouvernance doit donc proposer et susciter l’adhésion d’un cadre comportemental qui encourage l’appropriation, la collaboration, le partage et le respect de règles d’éthiques. Ce rôle fédérateur, visant à instaurer une gouvernance participative impliquant toutes les parties prenantes, constitue le plus grand défi pour la data gouvernance en particulier, mais aussi plus généralement pour le développement de l’économie de la donnée en général. La mise en application de la réglementation RGPD en Europe permet d’en illustrer les enjeux, les défis, et les impacts.
Cet article (ainsi que sa première partie) s’appuie sur une présentation réalisée pour le keynote des data days de KPC consulting à Paris. Cliquez ci-dessous pour accéder à la présentation dans sa totalité.